Resultado de aprendizaje (Temas del Tercer Parcial)
3.1 - Liberación y Despliegue Continuo de Software
El despliegue continuo (CD) es un proceso de lanzamiento de software que utiliza pruebas automatizadas para validar que todos los cambios en una base de código sean precisos y estén listos para implementarse de forma autónoma en un entorno de producción. Este ciclo de lanzamiento de software ha progresado y avanzado en los últimos años.
Con un enfoque de ingeniería de software, el CD ofrece funcionalidades de software con frecuencia a través de implementaciones automatizadas.
Como proceso de lanzamiento de software, CD prueba, verifica e inserta automáticamente nuevas piezas de código en un entorno de producción si pasan las pruebas automatizadas.
ENTREGA CONTINUA DE ARTEFACTOS A PREPRODUCCIÓN
El ciclo de vida o fases de la entrega continua, contiene 3 fases, y entre esas tres está la fase de Aprobar implementación, parte de acabar con las fases otras dos fases, ya que se tiene un producto «entregable», con un buen número de pruebas superadas (y si no las ha superado, lo podremos arreglar antes)
Es entonces el momento de realizar la implementación, de forma manual, en el entorno que deseemos. En estos casos, podemos entregar en un entorno de pruebas o preproducción, para la realización de pruebas manuales, o realizar alguna demostración de producto.
ENTREGA CONTINUA DE ARTEFACTOS EN AMBIENTE DE PRUEBAS
En el desarrollo de software tradicional se consideran diversas fases conocidas y comunes. Primero se realiza una etapa de especificación y análisis de requisitos, seguida de una fase de diseño y posteriormente de una fase de construcción del software. Este proceso genera como salida una serie de artefactos o piezas de software, que pasan por una etapa de validación a cargo de un equipo de control de calidad. Luego los usuarios aprueban estos artefactos, validando que las funcionalidades implementadas satisfacen los criterios de aceptación, prestablecidos en la fase de especificación de requisitos. Con la aprobación de los usuarios, se entrega el software al área de operaciones para que lo instale en el ambiente de producción. (RIQUELME, 2018)
DESPLIEGUE AUTOMATIZADO
¿Qué es el despliegue automatizado?
Según la empresa ILIMIT dice que, las empresas de desarrollo de software buscan la manera de entregar sus productos o mejoras de los mismos de una forma ágil y fiable a sus clientes. Para lograr este objetivo necesitan automatizar este proceso de entrega o despliegue, es decir, incluir los mecanismos y herramientas necesarias para realizar el despliegue sin la intervención humana.
Implementar herramientas de automatización dentro del proceso de desarrollo de software permite agilizar la entrega de un producto de software al reducir el tiempo invertido en el desarrollo del mismo. La integración continua, la entrega continua y el despliegue continuo proporcionan un modelo informático automatizado que permite distribuir las aplicaciones de manera más rápida, eficiente y segura
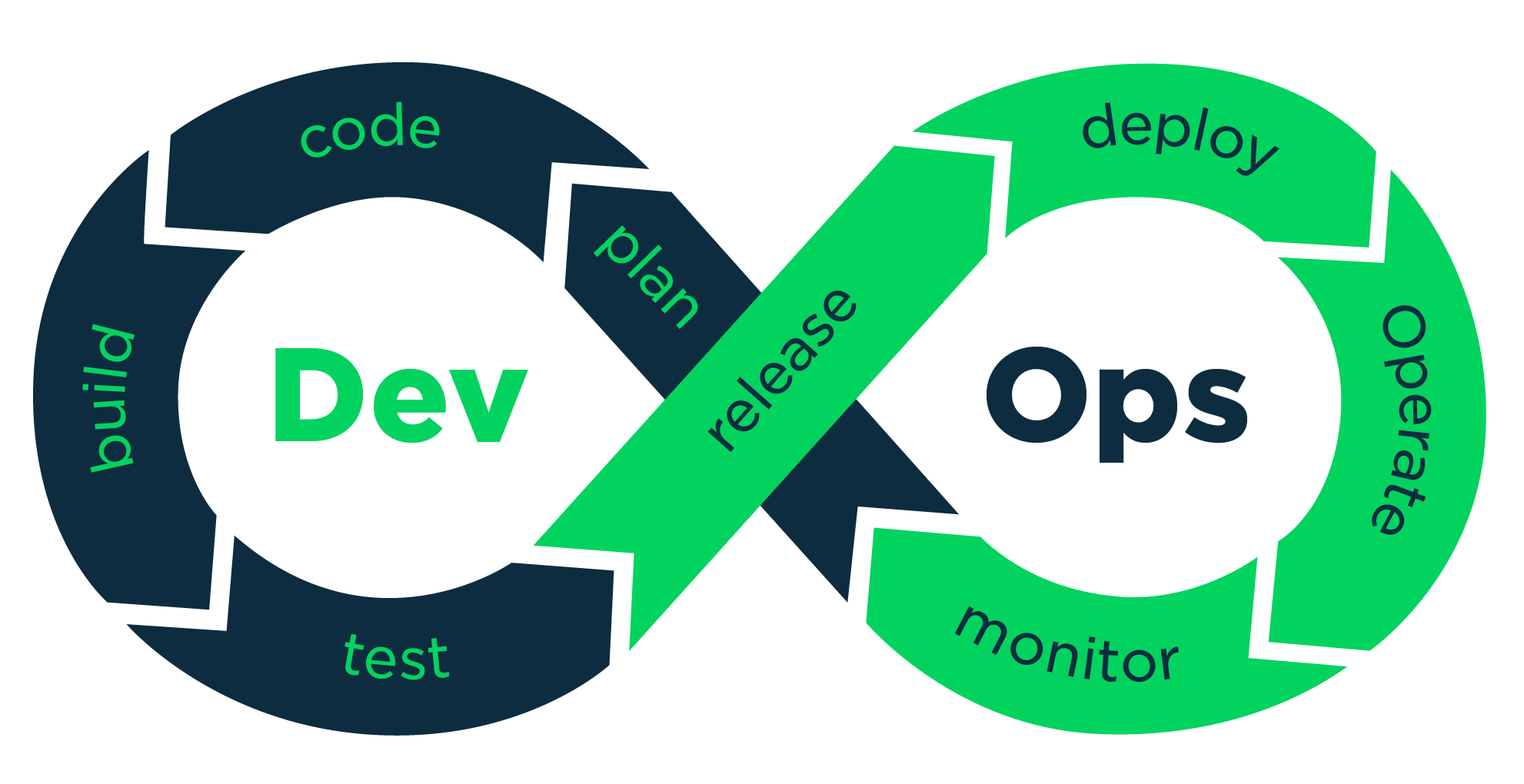
3.2 - Monitoreo de Software
Los tres pilares de el monitoreo de software son las métricas, los logs y las trazas. Estas tres entradas de datos se combinan para ofrecer una visión general de los sistemas en la nube y entornos de microservicios para ayudar a diagnosticar problemas que interfieren con los objetivos comerciales.
El monitoreo de un sistema, tiene que ver con tener una vista panorámica de los componentes externos y las comunicaciones entre ellos, es el primer paso para identificar problemas en un entorno distribuido.
Métricas
Disponibilidad de la aplicación
Los usuarios deben tener acceso ininterrumpido a su aplicación las 24 horas del día, los 7 días de la semana, a menos que se les haya advertido con anticipación que se debe realizar un mantenimiento programado. Medir la disponibilidad es una métrica simple para impulsar los recursos hacia el mantenimiento de una aplicación. Una vez que se lleva a cabo la implementación, la disponibilidad de una aplicación puede disminuir. El equipo de DevOps debe ser capaz de seguir los registros y revertir los cambios a su última versión disponible; sin embargo, las empresas que implementan sus aplicaciones miles de veces, de forma rutinaria, argumentaron que esto es más difícil de lo que parece.
Velocidad de las implementaciones
La velocidad de la implementación mide el tiempo necesario para completar una sola implementación. El tiempo de implementación de cada aplicación variará dependiendo del tamaño final del archivo. Cuantas más líneas de código, activos y dependencias, más tardará una aplicación en implementarse.
Un asunto a considerar es si resulta mejor asignar tareas una vez al día y construir lo que más se pueda, o si tiene más sentido aplicar múltiples y pequeños cambios en el transcurso del día.
Tiempo medio de detección (MTTD)
Como nos menciona Watson en su blog, cuando ocurren problemas, es importante que los identifiquemos rápidamente. Lo último que deseamos es tener una interrupción parcial o general importante del sistema y no saberlo. Tener una sólida supervisión de la aplicación y una buena cobertura en su lugar nos ayudará a detectar problemas rápidamente. Una vez que los detectamos, también debemos repararlos rápidamente. (Watson, 2017)
Tiempo medio de recuperación (MTTR)
Como menciona Maayan en su blog, esta métrica nos ayuda a rastrear cuánto tiempo lleva recuperarse de los fallos. Una medida clave para el negocio es mantener las fallas al mínimo y poder recuperarse de ellas rápidamente. Por lo general, se mide en horas y puede referirse a las horas de oficina, no a las horas del reloj. Tener buenas herramientas de monitoreo de aplicaciones para identificar rápidamente problemas y desplegar con rapidez la solución es importante para reducir nuestro tiempo medio de recuperación. (Maayan, 2021)
Tracers
Un seguimiento distribuido son datos que rastrean una solicitud de aplicación a medida que fluye a través de las distintas partes de una aplicación. El seguimiento registra cuánto tarda cada componente de la aplicación en procesar la solicitud y pasar el resultado al siguiente componente. Los seguimientos también pueden identificar qué partes de la aplicación desencadenan un error. (Tozzi, 2022)
Por otro lado, según una nota publicada por el sitio web Oreilly: Una traza es una representación de una serie de eventos distribuidos causalmente relacionados que codifican el flujo de solicitudes de extremo a extremo a través de un sistema distribuido.
Es decir que los rastros son una representación de los registros; la estructura de datos de las trazas se parece casi a la de un registro de eventos. Un solo seguimiento puede proporcionar visibilidad tanto de la ruta recorrida por una solicitud como de la estructura de una solicitud. La ruta de una solicitud permite a los ingenieros de software comprender los diferentes servicios involucrados en la
ruta de una solicitud, y la estructura de una solicitud ayuda a comprender las coyunturas y los efectos de la asincronía en la ejecución de una solicitud.
3.3 - Proceso de evaluación de rendimiento
El rendimiento es un aspecto del desarrollo de software que se centra en medir y mejorar el código. Después de leer este artículo, tendrá una idea mejor de: qué implica el rendimiento, por qué es importante para usted y sus clientes, y cómo empezar a medir el rendimiento de la aplicación.
Para comenzar a estudiar el tema se debe tener en cuenta que las pruebas de rendimiento son aquellas pruebas que someten a un sistema a una carga de trabajo con el fin de medir su velocidad, fiabilidad y estabilidad en esas condiciones de trabajo.
Acuerdo de nivel de servicio (SLA).
Respecto al blog ambit, un acuerdo de nivel de servicio (ANS) o SLA es un contrato que recoge los distintos productos o servicios que ofrece un proveedor a un cliente y que fija los requerimientos que el proveedor debe cumplir. En el sector TIC los SLA son el acuerdo sobre las normas de servicio que se realiza entre el proveedor de servicios y la empresa, profesional o particular que adquiere el servicio.(Ambit, 2022) Los SLA se crean para documentar los compromisos que piensa cumplir para los clientes. Los SLA especifican compromisos que son niveles de servicio acordados entre el proveedor de servicios y el cliente. Los compromisos de SLA se pueden medir de forma cualitativa o cuantitativa. Los compromisos de SLA pueden estar asociados con una o varias escalabilidades, que especifican las acciones que son necesarias si no se cumple el compromiso. ( IBM Corp, 2015)
¿Qué es un SLO?
Un SLO (objetivo de nivel de servicio) es un acuerdo enmarcado en un SLA sobre una métrica específica, como el tiempo de actividad o el tiempo de respuesta. Los SLO son los que establecen las expectativas de los clientes e indican a los equipos de TI y DevOps qué objetivos deben alcanzar y cuantificar. Los SLO son los que establecen las expectativas de los clientes e indican a los equipos de TI y DevOps qué objetivos deben alcanzar y cuantificar.
Disponer de SLO para esos sistemas internos es fundamental no solo para cumplir los objetivos empresariales, sino también para que los equipos internos puedan cumplir sus propios objetivos de cara al cliente.
Los parámetros y las métricas, se definen como los niveles de servicio que deben cumplir requisitos y que los proveedores de servicio deben mantener, como lo es un alto rendimiento, seguridad y estándares de cumplimiento a una estructura de costes asequible. Para alcanzar estos objetivos, las organizaciones deben comprender, medir y evaluar el comportamiento del servicio en función de unos objetivos bien definidos.
Indicador de nivel de servicio (SLI)
El Service Level Indicator, en español conocido como Nivel de Indicador de Servicio, se refiere a un tipo de métrica o medida relacionada con el rendimiento de un determinado servicio en la nube de cara a un objetivo determinado de nivel de servicio.
Destaca como un indicador para obtener datos e información que permitan analizar y medir el nivel de la calidad de los servicios que se ofrecen al público.
Un SLI (indicador de nivel de servicio) evalúa el cumplimiento de un SLO (objetivo de nivel de servicio).
Presupuesto de errores
Un presupuesto de errores es el plazo máximo que un sistema técnico puede fallar sin que haya consecuencias contractuales. Por ejemplo, si tu acuerdo de nivel de servicio (SLA) especifica que los sistemas funcionarán el 99,99 % del tiempo antes de que la empresa tenga que compensar a los clientes por la interrupción del servicio, eso significa que tu presupuesto de errores (o el tiempo que tus sistemas pueden estar caídos sin que haya consecuencias) es de 52 minutos y 35 segundos al año. (Atlassian, 2022)


Comentarios
Publicar un comentario